A Hacker's Guide to LLMs
Prior to completing this course, you should have a basic understanding of deep learning, which I initially lacked. I tackled it either way and plan to revisit it more extensively as I develop a prototype LLM application.
LLMs, or Large Language Models, essentially figure out the next word in a series of words, and give us the most probable one. There’s a great write-up on this by one of my favourite writers, Ted Chiang.
When using LLMs, we can communicate via tokens. These are either whole words, pieces of a word, or subword units. You’ll frequently hear the term ’tokenization’ bandied about; this is the process of creating tokens from a string.
For an LLM to accurately predict the next word in a sentence, it has to learn an extraordinary amount. Take the example statement, “The woman had a very unusual [word].” Most of us will rationally assume ‘day.’ For an LLM to produce that same prediction, it has to learn a lot about how the world works. Its ability to predict the next word varies based on its parameters.
 source: DALL-E
source: DALL-E
What does it mean when a neural network has parameters? Parameters describe the internal training of the model. This determines how the network processes input data to produce an output. I will elaborate further in future posts. For now, think of it as the size of the internal training data.
So, these AI models are essentially a form of lossy compression of real-world data. Because they are so comprehensive in their nature, it appears to be synthesis. It’s a matter of philosophy whether anything is happening, as it can be argued that we are also forms of lossy compressions with weights and biases.
When developing a language model, it typically goes through three phases.
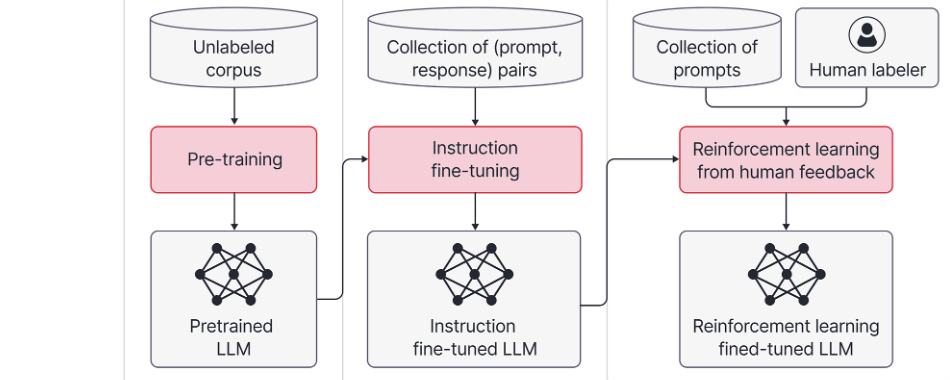
- Initially, there is pre-training: gather tons and tons of data. This requires tons of computing power (costs millions of dollars/numerous GPU Hours). Use this data with the GPUs to compress it into a neural network. Voilà. You have a predictor. Because they are so comprehensive in their predictive nature, it appears to be synthesis. This gives us a base model.
- Next is Instruction/Fine-tuning, which is a second phase where we refine the model based on available information. This is the stage that I often hear mentioned and find most challenging to understand. Let’s consider a quick analogy. Imagine you are a chef adjusting a recipe. You’re given a recipe (pre-trained LLM). You want to “cook” for different people, altering the model for different datasets. Now, you have a new recipe that’s been adapted to the new data. This is my mental model for Fine-tuning, Fine-tuning for dummies.
- Finally, there is the Classifier phase. This is where we use tools such as a better LLM or approaches like RLHF (Reinforcement Learning through Human Feedback). This involves a series of yes/no evaluations on the quality of its answers. It has been proposed that fine-tuning is enough, but opinions on this vary within academia.
Fun Fact: This is the reason why GPT gives incorrect answers. GPT-4 wasn’t trained to give correct answers. It was trained to give the most likely answers. This leads to its hallucinations. Additionally, the answers it gives are often very verbose because that is what humans preferred during the RLHF stage.
Quick UI Tip: I thought my understanding of the ChatGPT UI was decent, but I’m now becoming aware of some deficiencies. There’s a custom instruction section in ChatGPT. I usually prefer the answers to most of my questions explained at a high school level (don’t judge me), reasoned by the LLM, and given in bullet points. You can also provide a qualifier to ignore or alter this behavior. Very nice.
One of the issues commonly discussed online is around its ability to reason. Quite a few of these issues are, surprisingly, easy to debunk. In some cases, there is an issue of overfitting (has seen the response too many times, it just blurts something out), but this can be ironed out with some high-quality prompting. GPT also has plugins. The most impressive of which is its code interpreter. Description Below: Released two months ago, Code Interpreter was a new ChatGPT Plugin developed by OpenAI that allowed ChatGPT to do maths, upload and download files, analyze data, and — as you’d expect — create and interpret code. Impressive.
Giving AI Memory
Segue to actually building a custom application with ChatGPT. The code is hosted on a local or cloud machine but very much accessible. One of the key features of ChatGPT, compared to traditional AI systems, is that it is context-less. This means that information exchanges exist in the void and we need to do some advanced trickery to give ChatGPT a ‘Theory of Mind’. Aka, remembering what we were previously talking about, what my intentions are, and why.
One of the innovative ways of giving an LLM more memory is through a vector database. A vector database is a means of compressing data. This compression works via an embedding. Think of an embedding as a compression of some information that is especially good at keeping associations with the original information, compared to traditional compression. This is typically used as “extra memory,” to provide an LLM with a pool of information to draw from, used in the context window.
LLMs, as I’ve previously mentioned, don’t have a “memory”. This isn’t necessarily true. Otherwise, how would they recall any information? Their memory exists in two forms: the context window and the neural network.
Functional Tip: A really powerful feature of OpenAI is its retrieval-augmented generation, the ability of an LLM to append a retrieval system to its capabilities depending on need. For example, if you want to search a specific webpage, you can paste it into ChatGPT and tell it to summarize some information, essentially using the webpage as context.
This is a whirlwind tour of the basics of an LLM.
Note: This is a write-up of my notes, so it may not flow too well. Things don’t sink in unless I semi-study them. With that in mind, this is a code-first approach to language models.